How it works
Turbo4DGen identifies and removes redundant computations at multi-scale granularity in the SCM attention mechanism — at the token, block, and chain levels — through a rolling cache and an adaptive bypassing mechanism, while maintaining high generation quality. To the best of our knowledge, this is the first systematic framework for accelerating 4D generation.
Performance and efficiency
We report end-to-end latency, speedup, and peak memory across baselines. “✗” indicates an out-of-memory error; F and V denote the number of generated frames and views, respectively. Methods marked with “*” are not directly applicable to 4D generation, and their code is modified for fair evaluation.
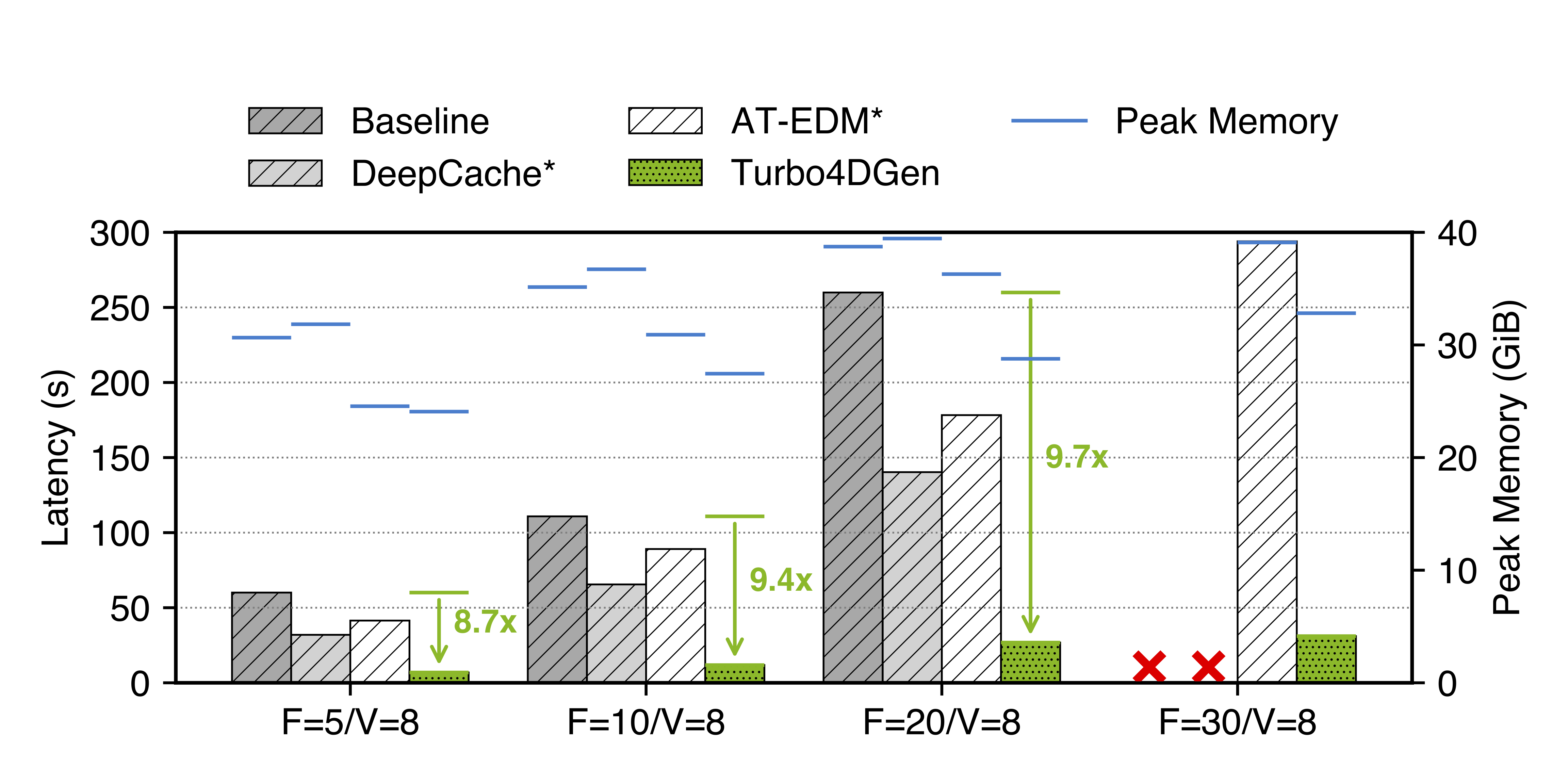
Comparisons on the iPhone dataset
We compare against TrajectoryCraft on five in-the-wild scenes. Each scene provides an input monocular video, a geometric warp render from a novel camera (incomplete, with holes), and a mask indicating regions to be filled. The diffusion model produces the completed novel-view output conditioned on these signals.
| Method | Apple | Block | Paper | Spin | Teddy |
|---|---|---|---|---|---|
| TrajectoryCraft | 256.1 / 1.0× | 263.2 / 1.0× | 264.5 / 1.0× | 296.7 / 1.0× | 276.6 / 1.0× |
| Ours | 52.3 / 4.9× | 51.6 / 5.1× | 56.3 / 4.7× | 57.1 / 5.2× | 57.6 / 4.8× |
monocular video
Comparisons on the Objaverse-Dy-4D dataset
We compare against the diffusion baseline on six dynamic objects from Objaverse-Dy-4D. Each clip shows synthesized novel-view trajectories over time at the indicated azimuth. Select a scene below.
BibTeX
@inproceedings{man2026turbo4dgen, title = {Turbo4DGen: Ultra-Fast Acceleration for 4D Generation}, author = {Man, Yuanbin and Huang, Ying and Ren, Zhile and Yin, Miao}, booktitle = {Proceedings of the International Conference on Machine Learning (ICML)}, year = {2026} }